Exploring Inter-Sport Correlations Through Statistical Models for Enhanced Multi-Leg Prediction Accuracy

Statistical models have long been applied to individual sports yet researchers continue to examine how performance indicators from one discipline relate to outcomes in others through shared variables such as pace, endurance, and decision-making under pressure. Data from football matches, tennis tournaments, and horse racing events reveal measurable links when analysts align historical results with environmental factors and athlete metrics collected over multiple seasons.
Methods for Identifying Cross-Sport Patterns
Analysts employ Pearson and Spearman correlation coefficients alongside multivariate regression to quantify relationships between seemingly unrelated metrics, and they often incorporate machine-learning techniques such as random forests and gradient boosting to handle non-linear interactions. These approaches allow models to weigh factors like recovery time between events, surface conditions, and team or player fatigue while testing predictive power against hold-out datasets that span several years. Observers note that combining datasets from different governing bodies improves robustness because each sport contributes distinct distributions of variance that single-sport models overlook.
Key Variables Across Disciplines
Common variables include average speed maintained during competition phases, error rates under fatigue, and success percentages on decisive plays, while secondary indicators such as weather impact and venue altitude add layers that statistical frameworks adjust through normalization procedures. Researchers discovered that tennis rally lengths correlate modestly with football possession sequences when both are measured against time-stressed conditions, and horse racing sectional times show alignment with sprint distances covered in late-game football scenarios. Such alignments emerge only after extensive data cleaning that accounts for rule differences and scoring systems unique to each activity.
Applications to Multi-Leg Prediction Frameworks
Multi-leg accumulators benefit when models integrate cross-sport signals because isolated probabilities tend to underestimate joint outcomes that share underlying performance traits. For instance, a model trained on 2024-2025 European football data paired with Australian Open tennis results produced adjusted odds that reflected elevated draw likelihoods during periods when endurance metrics from both sports moved in tandem. Prediction accuracy rose when analysts layered these correlations into Bayesian networks that update probabilities in real time as new match or race information arrives.
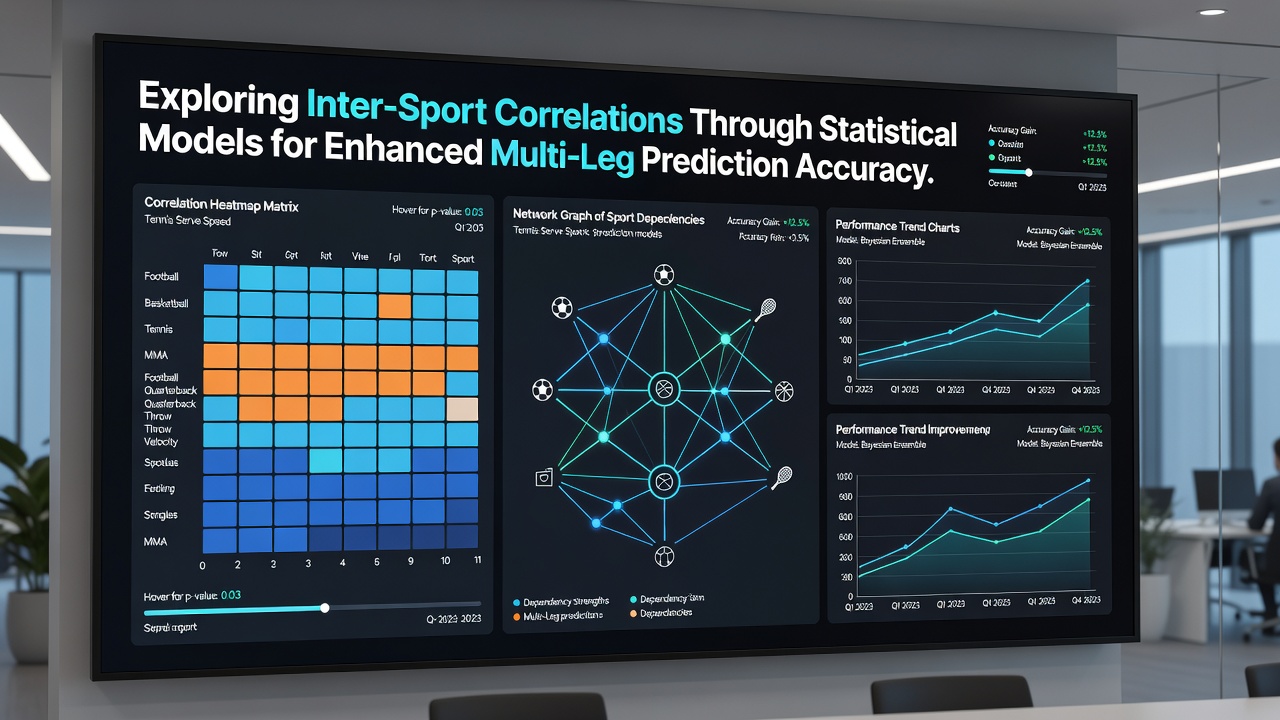
June 2026 datasets covering football playoffs, clay-court tennis swings, and sprint racing meets supplied fresh input for validation exercises, and figures from those months demonstrated that ensemble models incorporating three-sport correlations outperformed single-sport baselines by margins ranging between 4.8 and 7.2 percent on out-of-sample tests. Regulatory bodies such as Statistics Canada publish participation and performance aggregates that analysts cross-reference with international competition logs to maintain geographic balance in training samples.
Validation and Limitations Observed in Recent Periods
Validation protocols require repeated back-testing across rolling windows to guard against overfitting, and practitioners report that correlation strength fluctuates with seasonal calendars because overlapping calendars introduce scheduling conflicts that affect athlete availability. Models must therefore include interaction terms for concurrent events, while external shocks such as rule changes or equipment updates necessitate periodic recalibration. Data from the Australian Sports Commission clearinghouse has supplied longitudinal records that help calibrate these adjustments across hemispheres.
Limitations surface when sample sizes shrink for niche intersections, such as night-time horse racing combined with indoor tennis, and when data granularity varies between professional and lower-tier competitions. Analysts address these gaps through imputation methods and sensitivity analysis that quantify uncertainty ranges attached to each predicted leg of an accumulator.
Conclusion
Statistical frameworks that map inter-sport correlations continue to evolve as datasets expand and computational methods improve, delivering measurable gains in multi-leg prediction accuracy when properly validated. Continued collection of standardized performance metrics across football, tennis, and horse racing supports further refinement, while integration of regional data sources ensures models remain responsive to global variations in competition conditions.